




MTPE died today. Or yesterday maybe, I don't know. I got a report from the data team: "MTPE deceased. Funeral tomorrow. Faithfully yours." That doesn't mean anything. Maybe it was yesterday.
I had good fun writing that intro out, and kudos to anyone who catches my very forced reference, but today I am sitting down to write about something less literary and existentialist than the opening would have you believe (the reference is to Camus’s “The Stranger”).
I came to write about cold, hard data, and the pretty amazing things we have found at Bureau Works. My intro may have been thematically irrelevant, but the claim is exactly what I will be explaining here- MTPE is dead and Bureau Works killed it.
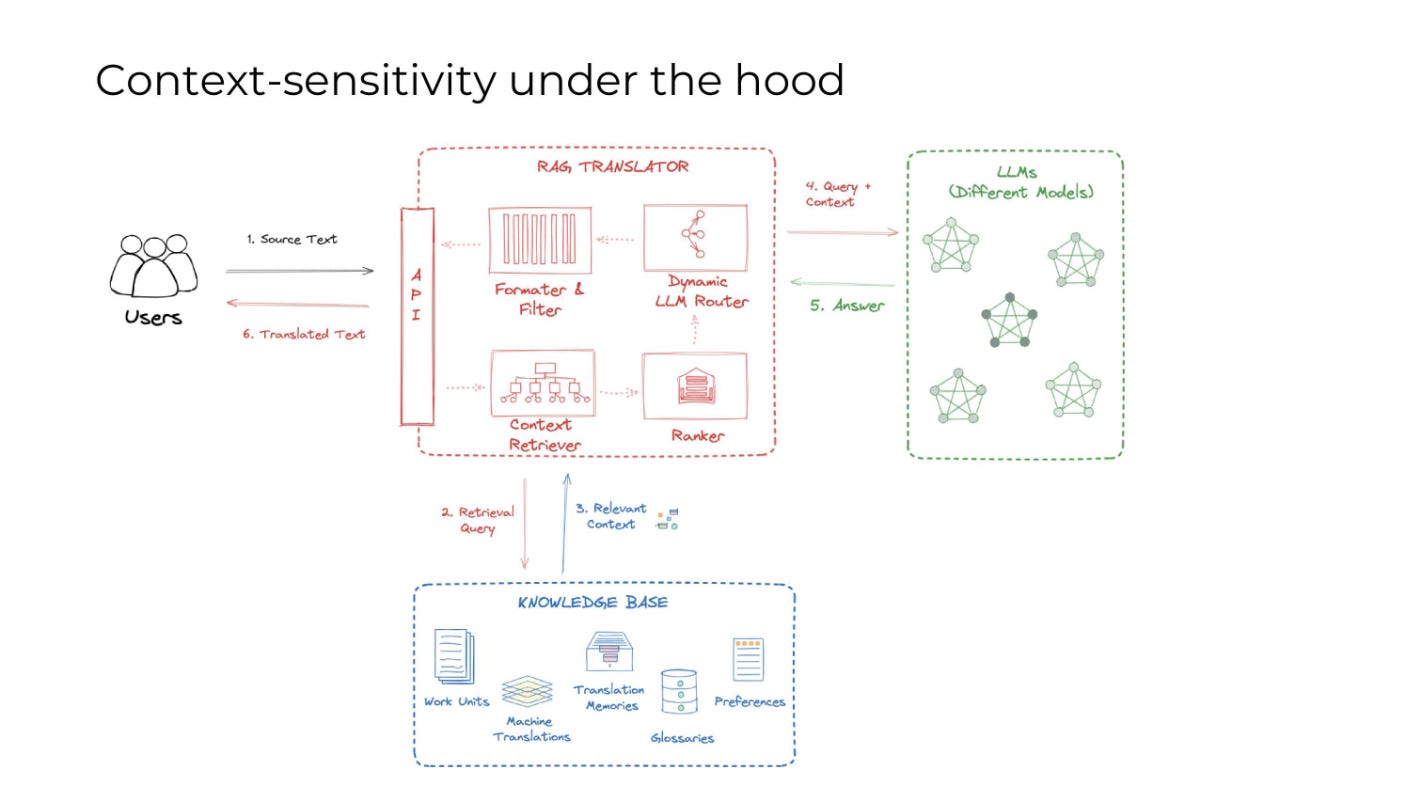
To make that claim, I need to explain a little bit about how our Context-Sensitive Translate works. Context-Sensitive Translate is the smoking gun that has taken down traditional MTPE- If you are already familiar with how the engine works, feel free to scroll down to the results section!

A Bold Claim
It is a bold claim to say that we have killed MTPE, but I stand by it. Here’s why:
In traditional post-editing, the translator analyzes a cold machine translation feed and has to verify a number of things:
Linguistic accuracy
Relevance of tone, voice, and style
Agreement with knowledge bases (Translation memory, glossaries, etc.)
Adherence to client preferences
And each time they change a segment to reflect those prerequisites, they move on to the next segment and leave those changes behind. This means the translator could be making the same set of changes to different segments over and over again.
On the other hand, our Context-sensitive translation brings the translator’s expertise into the text with each change. The engine learns from the translator’s changes and suggests updated feeds after each change or accepted suggestion.
In addition, Context-Sensitive Translate unifies all necessary context into a single feed. What this means is that the translator no longer needs to spend time and brain power on making sure the MT feeds align with TM and other parts of the knowledge base. The feed arrives as a product of ALL the relevant context, and then it adds the translator’s changes into its calculations. The result is a feed that starts out stronger than an MT feed, and then finishes as a product of the translator’s authorship much more efficiently.
This is AI, But Not in the Way You Think.
None of this was possible before the advent of LLMs. But, Bureau Works isn’t using the models to do the actual translation. This is where things get a little confusing.
When someone talks about using AI in translation it is often assumed that they are using a large language model to translate the text. This can be done, but the most popular criticism of this is accurate: It isn’t really any better than using NMT. Basically, you can use an LLM as a machine translation engine, but it is hardly anything to get excited about.
But that isn’t what we use the LLM for.
In Bureau Works, we are using the LLM to juggle all of the different pieces of context and weigh them to produce higher quality translation results. This means that the LLM is basically answering the question of “Considering the MT, the TM, the glossaries, and the changes the translator has already made, what is the best suggestion to make for this segment?”
And then, your action on that segment will be further information for the LLM to answer that same question in the next segment.
This analytical assistance that the LLM provides can help the translator preempt and avoid many of the issues we often see in machine translation feeds, like:
Additions and Omissions
Incorrect translations
Gender Bias
Subject-verb agreement
Awkward phrasing
Unnatural sentence structure
Incorrect register
The engine will either correct these issues and present a segment for confirmation or it will specifically highlight potential issues, all depending on how much context is available.
Here are some examples of issues the engine could flag:

Cool Theory, Does it Work? (Results)
Here is the real reason that I sat down to write today. Our team knew that this would work, and we have seen it working for a while now. But now we finally have some comprehensive numbers to back it up.
We analyzed over 4.3 million translated segments, about half translated with CST and then edited by a translator, and half translated through NMT and edited by a translator.
This analysis found that Context-Sensitive translation in Bureau Works was more effective and efficient than traditional MT + MTPE methods.
Our finding was that the Translation Error Rate (TER) improved by an average of 22.08% when using Context-Sensitive translate. In simple terms, this means that the translator had to change segments 22.08% less than when they were working in a traditional MTPE paradigm.
For more details on our methodology and results, check out the recap of our experiment here.
The reason I don’t want to take up too much time writing that information here is that I want to use this space to discuss two things that aren’t in our experiment recap:
The value of edit distance (which is used to calculate TER)
The importance of large data sets
Edit Distance and The Spectrum of Utility
Edit distance is controversial. It is controversial because it attempts to change words into numbers and measure them as such, a move that is not generally appreciated by language lovers.
(Side Note: This is also what Large Language Models do, although they do it much more elegantly).
The real weakness of edit distance is that it does not have any ability to measure semantic differences and similarities in words; it can only measure syntactical differences. Without going into too much detail, the weakness of edit distance can be seen in this example:
According to a traditional edit distance measurement, the word “stork” is closer to the word “store” than either the word “shop” or “market”. We can see that it is indeed structurally closer, but it is not closer in meaning. That, essentially, is the weakness of edit distance as a measurement tool: It doesn't measure words based on meaning, it measures them based on spelling.
However, a tool having an obvious weakness does not discount the tool from being useful. Edit distance can give us a rough idea of how much the translator needed to do to correct the segment, even if that idea is not perfect.
There will be plenty of times where edit distance measurements will indicate accurately whether the segment underwent major changes or minor changes, and there will be some instances in which edit distance does not properly represent the amount of work the translator completed (with edit distance either over or underrepresenting the amount of work).
But, as I mentioned before, “perfect” and “useless” are not the only two ways that we should be thinking about our tools. Utility is a spectrum, and every tool falls somewhere between perfect and useless. Exactly where on the spectrum a tool falls will depend on the context of the job, and edit distance is more useful when measuring volume of work than when measuring the quality of work. And, volume is exactly what we were measuring in this experiment.
This is why having a large number of segments to measure was crucial.
The More Data the Merrier
Because we were ultimately looking to measure the average volume of changes made when working with Context-Sensitive translate vs traditional MTPE, we needed to have enough data to validate our hypothesis. And, considering that we are well aware of the limitations of edit distance, we wanted to have enough data to even out any oddities.
With 4.3 million segments analyzed, we are confident that we have enough data to show a trend of fewer translator changes between the proposed segment and the segment that ultimately was confirmed. The extrapolation from this data is that the segments proposed by Context-Sensitive Translation in Bureau Works are more accurate than segments proposed by NMT alone.
So, what’s next?
Ok, so Context-Sensitive Translate produces a significantly lower TER. How does this impact the user?
The hypothesis we are currently testing is that TER is inversely correlated with speed, meaning that lower TER means faster translations. This is something we are seeing anecdotally across our current users, and we are currently testing it at scale in our lab.
The anecdotal result has been that our users have been able to translate more words in the same time frame, without sacrificing on quality. This has allowed them to take on more projects and bill more and/or take more time for themselves.
We are looking to see this replicated at scale, and we will do another report once we have our results. Subscribe to stay up to date on all findings from future experiments!