

The Generative Language Engine that Could
It's one thing to copy and paste content into GPT for translation. It's a completely different thing to truly harness its predictive capabilities through cutting edge machine learning practices.


Overview
Recent AI advances have provided us the ability to turn rigid knowledge management structural frameworks into flexible, dynamic, and context-aware fluid processes. The 70 billion-dollar question is how can we build technology in a way that makes sense for translators, agencies, and content owners so that we increase output and quality while highlighting human creative and intuitive prowess.
Background
Translation Memories and Glossaries
Knowledge management has been one of the perennial cornerstone issues in translation and localization. Simple questions like:
How do you make sure that a translator remembers at all times the standards and conventions preferred by a given client?
How do you ensure a translator can translate while keeping in mind what other peers are doing when working in parallel on the same or similar project?
How do you ensure that the same content does not have to be translated twice?
Tech-driven rigid databases such as translation memories and glossaries were groundbreaking responses to these questions 40 years ago. They changed the game and greatly augmented a translator's pneumonic and productive capability. Through them, a translator could be reminded of a countless list of terms as well as similarly or identically translated sentences living in a particular linguistic corpus.
Memory became no longer a thing of the mind, or of the books, but of the machine.
The problem with this solution lay in its rigidity. Translated sentences and terms were stored in databases and new sentences were processed against these databases looking for identical or non-identical matches (tenderly referred to as fuzzies in our industry). Here are a few examples of rigidity:
Glossary Vs. Memory: A sentence stored in the translation memory contains terms that are different from those in the glossary
Lack of inflected forms: A glossary term such as “run” would not find any matches when looking for the word “ran”
A sentence stored in the translation memory contained semantic or syntactic errors that would never get fixed in perfect matches
These may seem like small issues but when you scale them across billions and billions of words translated yearly by translators they mushroom up into colossal linguistic shit-shows with expensive and hard-to-deal-with repercussions for the translation community and content owners.
In addition, other problems contributed to linguistic managerial complexity:
Translation memories that contained dated forms of expression that would not get refreshed over the years
Glossaries that were either too big turning any sentence into a term nightmare or too small leaving it all up to the discretion of each translator
Certain kinds of fuzzy matches would often induce errors when the sentence structure was nearly identical but numbers or key semantic determiners deviated slightly in edit distance but significantly in terms of meaning
Fuzzy matches below a certain threshold (varies according to context) would often result in more work fixing than translating from scratch
But don’t get me wrong. Despite these shortcomings, translation memories and glossaries were night and day when it came to global content production. They were the difference between making it or breaking it.

Enter Machine Translation
For many years machine translation was an entirely separate track. Statistical, Rule-Based, and/or Neural Machine Translation (later) existed but were parallel solutions for preprocessing large bodies of text with low sensitivity or particular use cases. Eventually by the 2010s and beyond Machine Translation became more began to work more closely with Translation Management Systems offering a potentially productive alternative to pre-populate sentences that were not present in the translation memory so that a translator could at least have a rough draft to start from.
This shift introduced even more complexity to this hallucinating multilingual scrabble.
Now you had situations where Machine Translation suggested translations that deviated entirely from Translation Memories and Glossaries and while in certain contexts (simple sentence structure and specific language combinations) results were helpful and acceptable, blunders and bloopers happened all the time allowing it to fall in the sphere of ridicule in the translation community. For many years, and maybe to this date, Google Translate (despite its engineering marvel) became synonymous with a superficial and decontextualized translation.
Machine Translation Training and Tuning as a Mitigator

Generic Machine Translation does not follow glossaries or incorporate Translation Memories into its linguistic corpus. Not a problem. Trained Machine Translation is here to save the day. With trained machine translation you can feed your linguistic corpus into a Machine Translation model and have it behave closer to your expectations. By having machine translation engineers tune these models, you can get them to improve as well. Problem solved. Not quite…
But first, What is the difference between Tuning and Training MT?
Without getting into details, tuning a machine translation model refers to the process of tweaking the weights and properties of the model itself. For an example of the thought process involved in tuning a machine translation model please refer to this study by Sara Stymne at the Uppsala University here.

Training a machine translation model does not change the properties of the model itself. Rather training focuses on changing the scope of the linguistic corpus referenced by the model to induce certain results over others. If you are training an automotive MT and feeding it with a linguistic corpus containing specific automotive sentences and terminology you are likely to get far better results than working with a model that taps into a variety of content types and domains.
This sounds amazing! Why doesn’t it work?

It works all right. If you throw a ton of money and resources continuously and incessantly at getting machine translation to perform well in a given domain and language pairs it’s likely you’ll see amazing results. The challenge is that you’ll make it work for automotive English in German for instance but then have to start the tweaking problem all over again when working with English in Spanish or Simplified Chinese.
Machine Translation tuning is a complex Natural Language Processing (NLP) challenge that falls within the machine learning domain requiring highly skilled and rare (another word for expensive and hard to find) talent. Tuning is a research and development process with mixed results that requires time, trial, and error and is not a great fit for the pressures of the localization world that needs scalable results fast.
Machine Translation training is far less complex but requires localization engineers to train models on an ongoing basis to ensure that translation memory updates get incorporated, glossary terms get updated, and results are consistently measured and worked on so that it may operate on a path of continuous improvement.
In a nutshell, machine translation tuning is meant for NLP researchers while machine translation training can be managed by localization engineers. Both require continuous labor and effort and produce good results on a limited scope (domain + language combination). This makes these options only effective for a few organizations that have enough volume and domain specificity that ensures the economic feasibility of such an enterprise.
These are feasible options for large global enterprises but distant like the nearest star to freelance translators or small and medium-sized translation agencies, and organizations that operate with multilingual content.
And in addition, besides all of these challenges, machine translation does not work all that well when the content is less straightforward containing more metaphors, implicit contextual cultural references, idioms, and other linguistic particularities that do not have a clear 1:1 correspondence between original and translated text.
To summarize, optimizing machine translation is:
Expensive
Time-consuming
Domain-specific
Language-specific
Mixed results when working with less straightforward content
Have no fear!
The Generative Language Engine is here!

So far we have outlined some of the challenges around integrating linguistic knowledge and preferences through translation memories, machine translation, and glossaries. If you thought this would be a dead-end, you thought wrong. :) This is where our road begins.
With the advent of large language models, particularly levels achieved by GPT-3 and beyond, the entire paradigm of linguistic knowledge management could be flipped on its head.
Our machine learning engineers have been able to work with a combination of large language models and natural language processing techniques to produce a single feed that is sensitive to your machine translation, your translation memory, and your glossary preferences in a dynamic way that operates seamlessly in run-time. It’s fast, cost-effective, and turns many of the problems described above into non-issues.
Machine Translation Feed Doesn’t Factor Your Glossary? Problem Solved!
In this example below notice how on the left-hand side we have 6 terms highlighted in yellow identified as glossary terms. The selected feed on the right was translated into Brazilian Portuguese by untrained Microsoft Machine Translation. The machine translation contains no errors but it does not follow the suggested terminology.
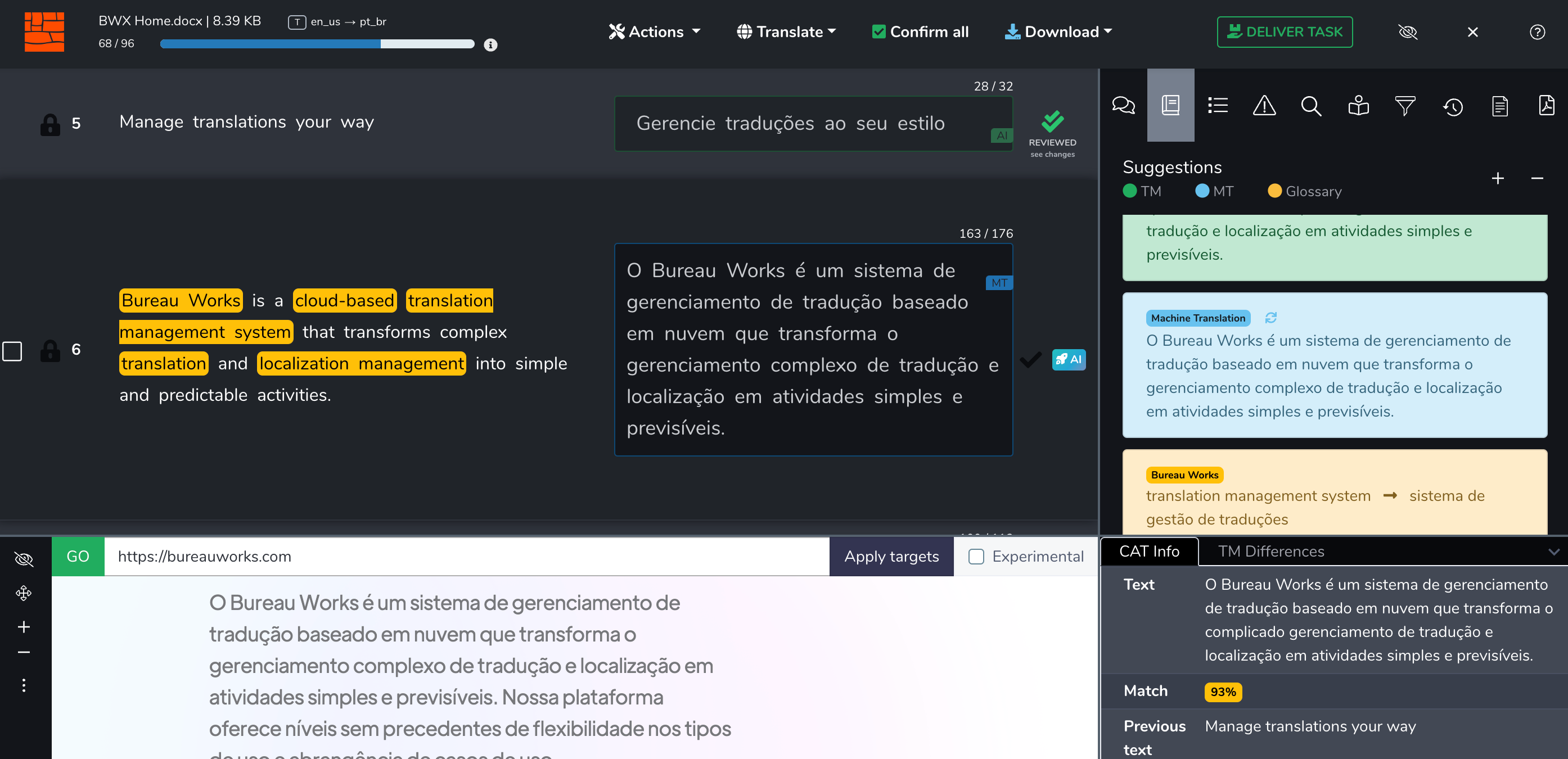
Now if I process this same sentence through our GLE, notice how all glossary terms are applied to the translation.

And it’s not just that these terms were clumsily injected into the translation. The sentence was reorganized where necessary to be read fluently and cohesively. And if that does not raise your eyebrows. Maybe this will.
Translation Memory feed is not aligned with your latest glossary and translations? Our GLE takes it all the way.
In this case, below we have a 92% feed originating from the translation memory. The stored translation has a few content deviations from the newly processed translation which would typically result in manual work linguistic adjustment so that it correctly mirrors the current segment. In addition, the stored translation did not take into account the latest changes to the glossary.

In our current paradigm, a translator will have to look for the differences, implement them to the TM feed, then go through the glossary to apply proper terminology, and then once all of that heavy lifting is complete, begin to focus on reading through and editing the sentence.
Forget all of that. Our GLE will teach large language models to fix the sentence taking into account the translation memory, the suggested machine translation, and the glossary to create a single mesh that will require minimal additional manual work. In this case, a simple confirmation would suffice as you can see below.

But what’s even more amazing is that…
Fuzzy Translation Memory Matches Become Close to Exact Matches
In the example below, segment 34 has a 62% translation memory match. The translation memory feed departs significantly from the machine translation suggestion as it adds a word to emphasize the “uniqueness” of “One” and it also uses “them all” in the feminine form.
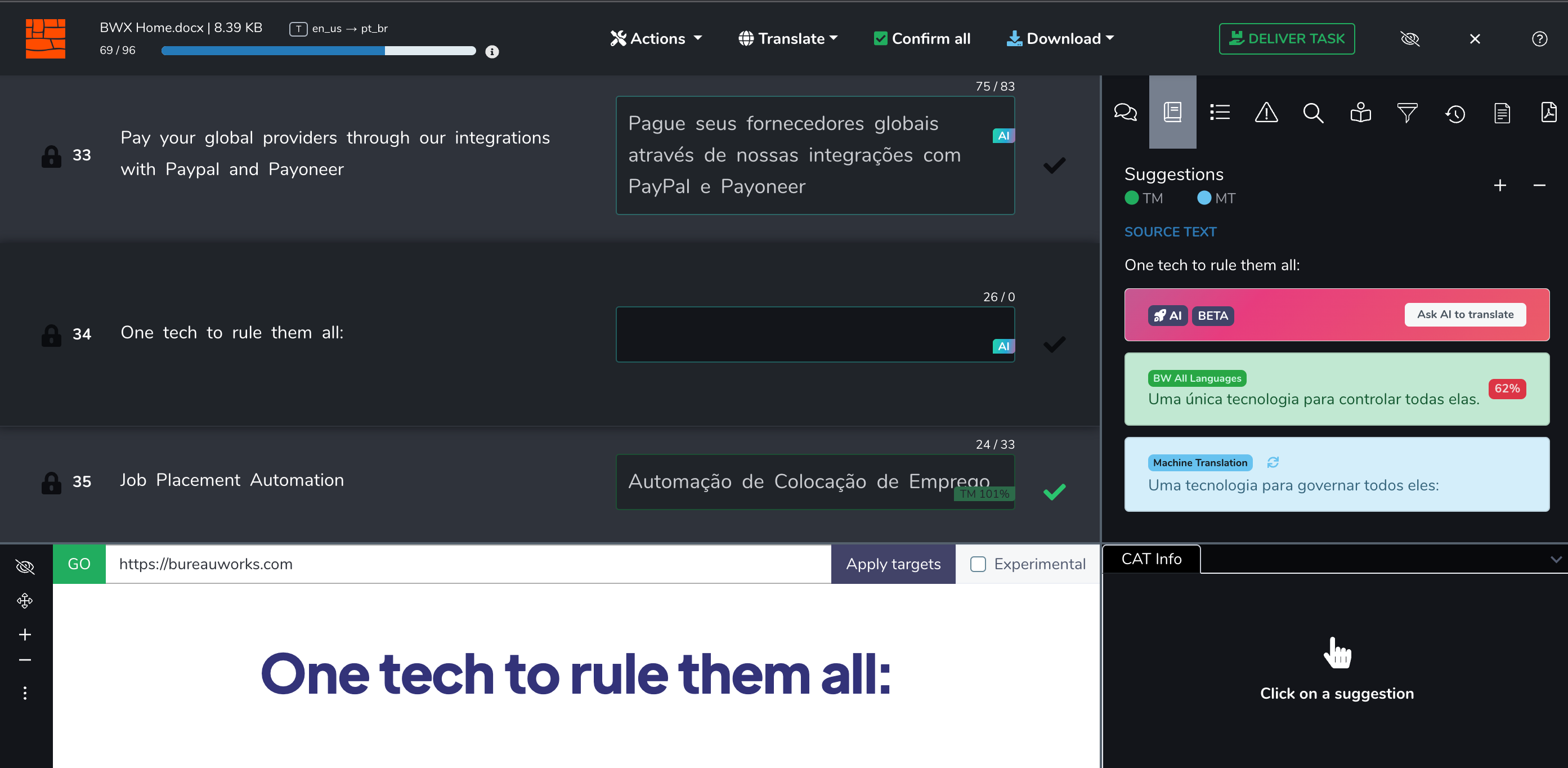
This would be a typical case where a translator would have to pay close attention to the differences in stored translation vs. newly processed translation to implement them accurately.

But that’s no longer the case. Our GLE can take into account the stylistic choices encompassed in the Translation Memory, factor into account the machine translation as well but with reduced emphasis, and produce a feed that is ready for the translator to sign off on without deviating significantly from the contextual intricacies stored in the TM. Notice however that the TM feed had the idea of “control” whereas the GLE suggested “govern” for the concept of ruling present in the source.

The GLE as a predictive engine takes certain liberties when it believes there is a higher probability of success by deviating from the corpus. In my particular opinion the choice was a good one as the idea of “governing” describes more accurately the all-encompassing nature of the tech than “controlling”.
You can teach it on the fly
But let’s say you are not happy with the liberties taken by your assistant. Not a problem. You can teach it.
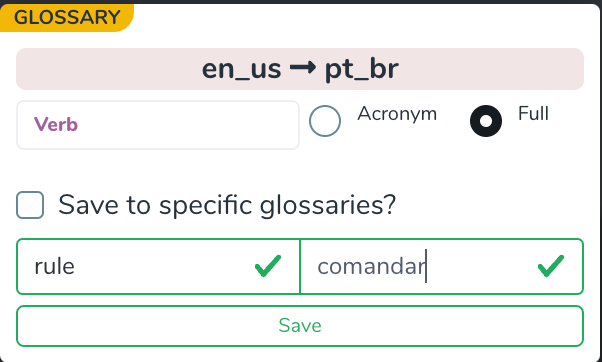
Let’s say we want to emphasize the concept of “commanding”. We add that to the glossary on the fly and ask the GLE to think again.

As a trusted disciple, sure enough, our GLE now did its best to factor in that terminology and produced a sentence feed that was mindful both of the fuzzy TM match and what I just taught it.
But I don’t feel 100% about it. No problem. I’ll ask my second pair of eyes to take a look at this sentence.

My second set of eyes in BWX is intentionally unaware of the context so that it can approach the text in a way that would mirror how a random third party would approach this. I don’t necessarily agree with its opinion but it felt good to think about it from a different perspective and still follow through with my own choices.
It feels like magic - but there is nothing magical about it

Our GLE is using a variety of natural language processing and machine learning techniques to deconstruct language into tokens, dynamically indexing and assigning different weights to each of these tokens and then interacting with LLMs such as GPT-3, 3.5, and 4 to both teach and learn while it assists users in minimizing their effort to arrive at their desired output.
It’s Constantly Context-Aware
Unlike trained engines that may be aware of some aspects of the corpus living in the past, GLE is not only aware of the present but also aware of a wider range of contexts and meta-contexts that help it make better decisions. With trained machine translation it’s very challenging to keep up with the latest and the greatest even if you have a dedicated team and the right tech in place to continuously retrain your engine based on the latest translation confirmed, or the latest addition/modification to your glossary.
Its awareness is broad
Instead of simply being aware of the linguistic corpus, our GLE can take into account multiple contexts and data points to make informed textual decisions. We can have it observe things such as:
the translation history for that segment (how different translations for that segment evolved)
the latest terminology with far more contextual information than a part of speech or other classifiers to have more discretion of whether or not a term does belong in a given context
sentences above and below to ensure readability and have optimized linguistic flow rather than seeing sentences that don’t seem neatly stitched together
domain so that it knows that marketing web copy, for instance, should use increased temperature when compared to an engineering manual for instance
intent so that it factors in what the goal of the document is to adjust the tone accordingly. is the goal to inform or to get someone excited? to alert and gain consent or to move someone closer to a purchase decision?
It’s Dynamic -
The learning takes place in run time. The second you add a term to your glossary or change a translation memory feed, it’s learning from your actions. As you change things, it’s learning and adapting to your preferences on the fly.
It’s Learning -
Every term you add to your glossary will be taken into account. Every sentence you add to the translation memory will be taken into account. The changes you make to its suggestions will be taken into account. The engine never stops learning even if you are not deliberately trying to teach it.
It’s Recursive -
You can continuously dialogue with our GLE to get the results you are looking for. In the same sentence for instance, you can add a term to the glossary, read the AI suggestion, ask for a second pair of AI eyes to review it, change the glossary, and regenerate the AI suggestion until you are satisfied with the work within your feedback loop.
And how about the results?
The science behind all sounds great. But does it produce results?

Our data is at this point preliminary because:
Implementation is recent
The engine learns continuously making initial results less interesting than results down the line
Users are still getting used to this new paradigm
Statistical sampling is in the tens of thousands of segments only across twenty languages and our goal is to have more representative data once we reach the millions of segments in over one hundred languages in this framework
But even with these disclaimers, we can already see more than a 50% drop in edit distance to take a translation to professional grade when compared to Microsoft Machine Translation feeds.
While Microsoft requires on average translators in our platform close to 40% of changes to the feed to confirm a segment, our GLE is already operating at close to 15%. Nothing concrete enough that I would bet my life on, but most definitely promising.
Limitations and Challenges

As much as I would love this article to be a promotional piece on how our Generative Language Engine will change everything, it’s not. We are in the early stages of this recent wave of AI breakthroughs opened up by Open AI. And as with any early-stage paradigm-shattering tech, it’s not clear exactly how things are going to unfold…at least for me.
Adoption
It’s hard to break free from a certain way of doing things. Some organizations take years to fully implement a traditional translation management system, and changing the tool alone is by itself a huge undertaking that is only typically carried out when there is a major pain or incentive e.g. the tool is not working properly, it’s costing 3x budget, etc…
But the hardest thing to overcome is that in this case we are not simply talking about swapping tools. We are talking about swapping paradigms which require even more bandwidth and commitment from all parties involved.
Mindset
AI does not stir up the same feelings in everyone. Excited, Scared, Skeptical, Curious. AI is something different for everyone. For me for instance AI is something different at every moment. On the same day, I can go from being bullishly excited to fearing the uncertainty it’s opening up. And the reason I bring up mindset is that it’s hard to follow through with something that we still feel dubious about.
AI Behavior is weird sometimes
LLMs are probabilistic engines meaning that their decisions are based on probabilities as opposed to linear 1:1 input: output relationships. If you store in a database for instance that the word Apple is X in another language and you query that database for the translation of Apple, it will return 99.99999999% of the time (because 100% doesn’t exist) X. With a probabilistic engine it may return X but it may return Y or Z if the parameters of the system trigger that there is a greater possibility of Y or Z in a given context. This potential for inconsistency in AI is expected and even exciting for most researchers I talk to but for people managing organizations, it’s often not convenient or even acceptable. It may make decisions on occasion that are not in agreement with user expectations or even past responses. In generative AI everything is a probability and that’s just not a way that most users are used to thinking about computing.
Performance -
Performance is still a huge issue when it comes to AI. Open AI alone is spending over 700k a day just to run its servers. You can read more about it here. The computing cost makes it so that they have to work with low API rate limits and high response times. Currently, Open AI as a standard prevents an organization to spend any more than a whopping $120 per month on tokens.
This makes it both technically complex and prohibitively expensive to build systems that rely on Open AI or Microsoft’s Azure APIs. Unless performance is fundamentally addressed it’s hard to see in practice AI scale as some people may imagine it will.
The Next Frontier - Transforming User Choices and Behavior into Language Learning

We are already witnessing a shift in frameworks and possibilities when it comes to traditional language management structures. As this article shows, there already are better choices than the Translation Memory, Machine Translation, and Glossary combo available out there, ready to be used.
But what does this mean as far as future possibilities?

Learning is such a fascinating concept. As a student for instance you can learn simply from your teacher’s words. But this concept of learning begins to mushroom exponentially when you add other sources of information. You can learn from your notes. You can learn from your notetaking process and improve it as you take your notes. You can learn from your teacher’s tone, demeanor, and mannerisms. And you can learn from all of the inferences and connections you make from all of these components described above.
The point is that learning is dynamic, draws from a plethora of sources of information, and continuously correlates both information that is explicit as well as a trove of implicit information. The better the learner, in principle, the more connections are established between a wider range of contexts and sources.
With our Generative Language Engine, the concept is analogous. It’s learning already but the student can evolve their mastery over learning. The engine can learn not just from the choices that are made but from those that are not made. Our GLE can learn to fine-tune ever more closely to the text intent and target demographic as it draws from both obvious contextual sources such as websites, as well as unobvious contextual sources such as whether we are in the holiday season or closer to mid-year.
Every action can be infinitely deconstructed, learned from, and then extrapolated into predictions over what the next action is likely to be. As these engines become better at learning, they are likely to become better at predicting which in our case means less grunt work and more thought work for people to come in and think more critically about whether something truly makes sense in a given context as opposed to moving tags around to ensure formatting consistency.
We are talking about elevating the work with language so that it has to do more with hyper-messaging analysis, more focus on how content performs, more focus on iterating over the same content/translated content until it produces desired outcomes, and less work over completing a given assignment.
Behind all of this framework lies the core assumption that we are here first and foremost to work together as a species to improve our condition while experiencing this amazing gift and burden called the subjective human experience. Corny and optimistic, I know. But I believe in this, and seeing glimpses of this in action continues to push me forward ever so strongly. But what are your thoughts on all of this? I’d love to know.